Technology
DeepDependency
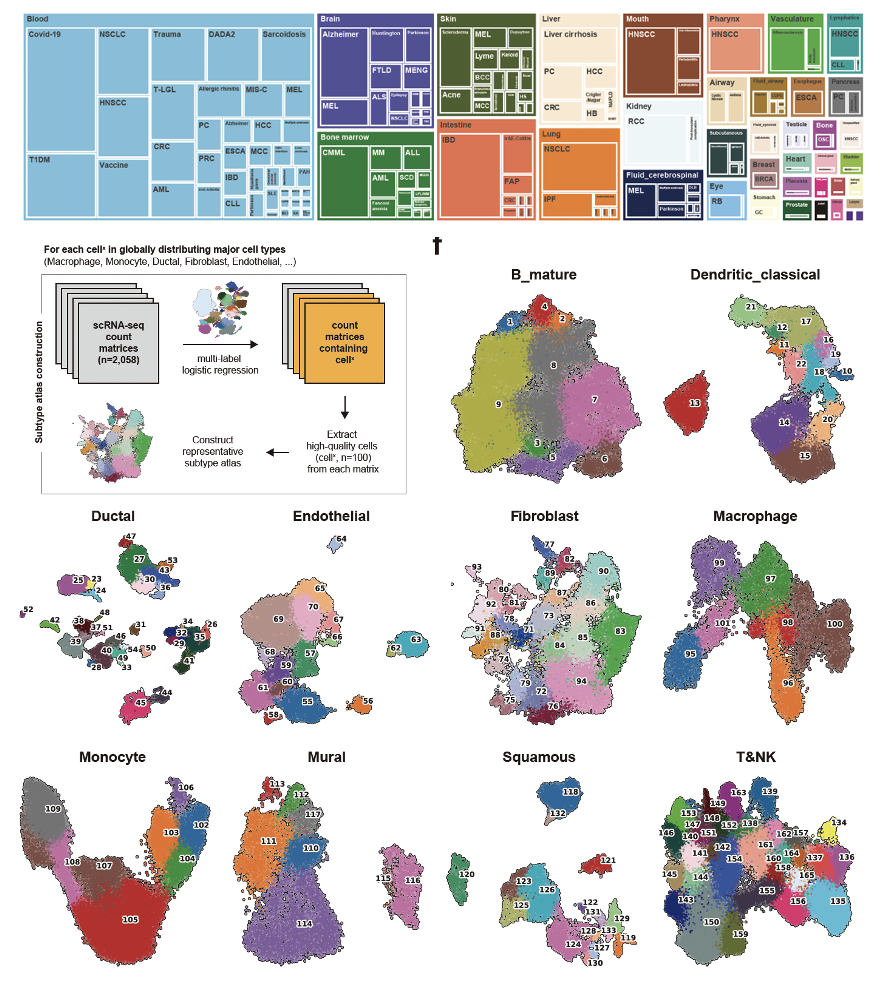
데이터 웨어하우스는 자동 웹 크롤링으로 수집한 GEO의 단일세포(Single-cell) 및 공간(Spatial) 데이터를 체계적인 수동 큐레이션으로 정제하여 구축되었습니다. 100가지 이상의 질병 유형에 걸쳐 약 5,000만 개의 세포 데이터로 구성되어 있으며, 모든 데이터는 단일 플랫폼에서 FASTQ 파일부터 직접 리매핑하여 배치 효과(Batch Effect)를 최소화하고 데이터의 일관성을 확보하였습니다.

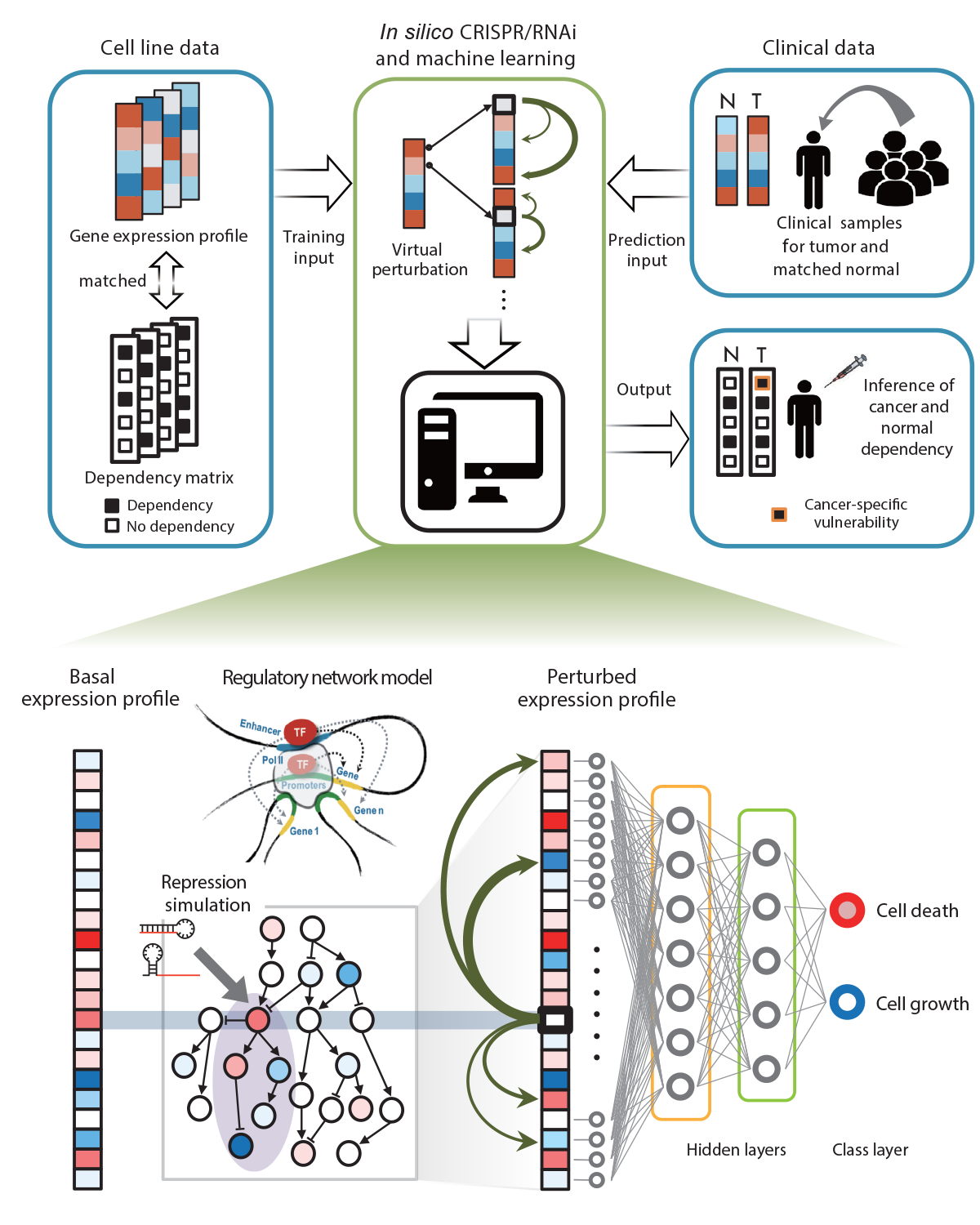
- Neogenlogic’s proprietary algorithm, DeepDependency, identifies neoantigens originating from cancer dependencies—genes that are essential for the survival and fitness of tumor cells
- Cancer dependencies can be evaluated either through an AI-based method—the “dependency predictor”—or through a database-driven approach that utilizes Neogenlogic’s internal data warehouse.
Dependency predictor
- The dependency predictor is a deep learning–based method that identifies tumor-specific vulnerabilities by leveraging extensive CRISPR/RNAi screening data.
- Based on the gene regulatory network, it infers sample-specific dependency profiles directly from the patient’s transcriptome data.
Data warehouse
- Genes that are essential for cancer growth tend to be homogenously expressed across individual cells.
- Neogenlogic’s world-class single-cell data warehouse provides a framework for identifying cancer dependencies, enabling the development of more effective anti-cancer vaccines.